The Never-Ending AI Race: Elon Musk's Grok 3 Joins the Battle

Introduction
Another week, another large language model (LLM) claiming to be the best. This time, it's Grok 3, the latest AI model from Elon Musk’s xAI. Just a few weeks ago, DeepSeek made similar claims about its latest release. Before that, it was OpenAI’s ChatGPT-4o and Anthropic’s Claude 3.5. The pace of AI development is relentless, and with each passing week, a new contender emerges, promising to outperform all others.
But here’s the real question: They can’t all be the best, can they?
Performance?
Grok 3's performance benchmarks, as released by xAI, suggest significant improvements over its predecessors. According to initial reports, Grok 3 outperforms many existing models in reasoning, coding, and general language understanding. xAI claims that it has made strides in mathematical problem-solving and contextual comprehension, putting it in competition with models like ChatGPT-4o and Claude 3.5. However, while these results look promising on paper, independent third-party evaluations are still necessary to validate xAI’s claims. Additionally, benchmarks often fail to capture real-world usability, meaning Grok 3’s actual effectiveness will depend on how well it handles diverse user interactions beyond controlled test environments. Here is a chart of Grok's claims.
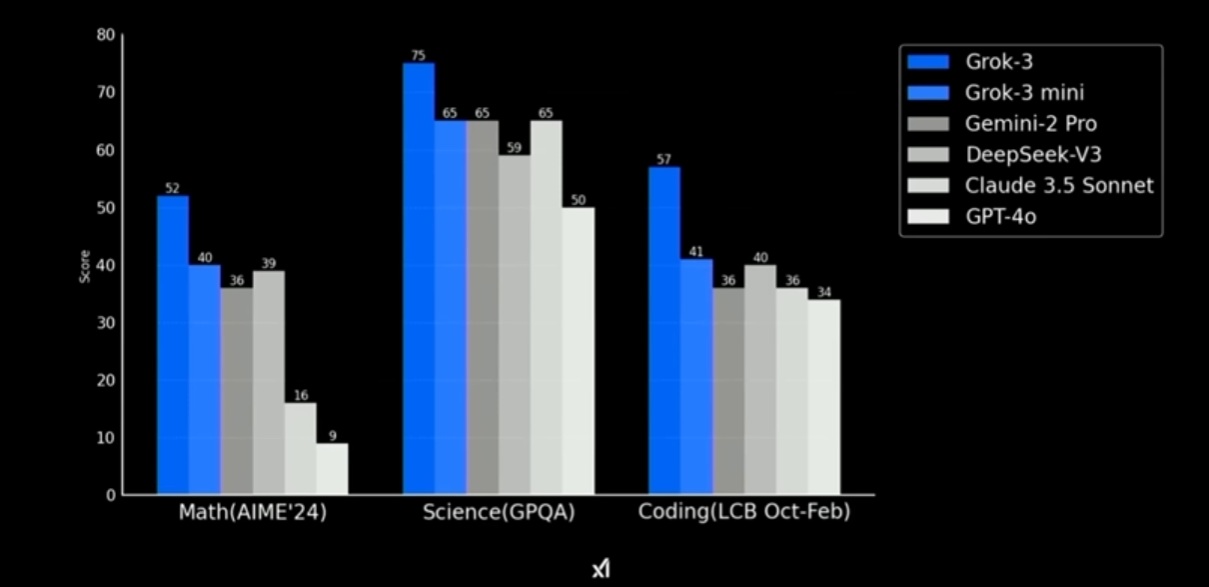
Here is a video on the Grok announcement.
Performance vs. Cost: Who’s Winning?
Grok 3 is being positioned as a highly capable AI model, and xAI has provided performance benchmarks to back up its claims. In this article, I’ll include a chart of Grok’s performance relative to other leading LLMs, as well as a video of its official announcement.
However, raw performance is only part of the story. Cost matters too. While companies boast about speed, accuracy, and reasoning ability, the real-world impact of these models also depends on how much they cost to run. Below, I provide a cost-per-million-token comparison for Grok 3, DeepSeek V3, ChatGPT-4o, and Claude 3.5. Here is a chart in terms of the lastest LLM models in the competion.
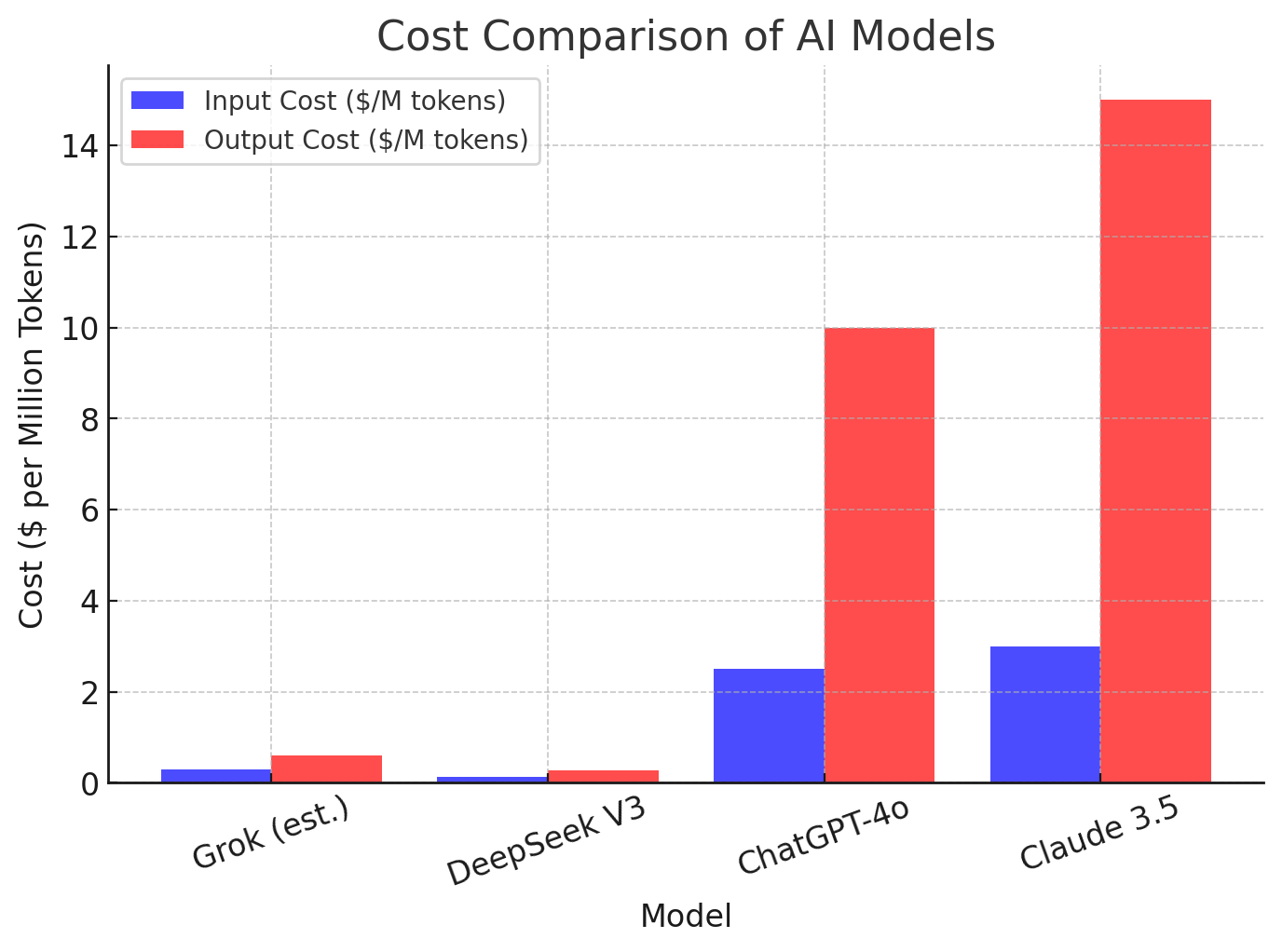
Beyond the Numbers: Features Matter
Cost and performance aren’t the only differentiators. Features are also a battleground. For example, ChatGPT-4o can generate real-time graphs in response to prompts, making it a powerful tool for data analysis. As of now, Grok 3 does not have this capability.
DeepSeek has positioned itself as the most cost-effective option in the LLM race, offering significantly lower prices per million tokens compared to competitors. However, despite its affordability, the model is currently facing major scaling issues, making access difficult for many users. As of this post, users cannot even purchase tokens to use the system, highlighting potential challenges in DeepSeek’s infrastructure. Additionally, payment options remain limited—U.S. customers, for example, can only pay via PayPal, which may deter some potential users. While DeepSeek’s pricing is attractive, these operational hurdles could slow down its adoption and limit its competitiveness in the rapidly evolving AI landscape.
Every model is innovating in different ways. Some are focusing on affordability, while others push the boundaries of reasoning and creativity. The question is: What matters most to users?
Conclusion
The AI race is accelerating, and with each new model release, companies claim to have created the ultimate LLM. But in reality, AI isn’t a one-size-fits-all game. Different users have different needs—whether it’s cost efficiency, accuracy, speed, or advanced features.
So, while Grok 3 is the latest competitor, it certainly won’t be the last. The real question is not just who’s the best today, but who will stay ahead in the long run.