Straight talk from Mensa who's read the research so you don't have to spend so mu...😝!ch time for your Busine$$!
{kind=link}
All Papers Referenced down below...
I know i kno...
Everyone's pitching RAG like it's the holy grail of AI. But here's the thing—not all RAG is created equal. If you're still selling vanilla RAG to enterprises in 2026, you're basically bringing a knife to a gunfight.
Let me break down when GraphRAG actually matters (and when it doesn't). No F**ing ! #BS, just science and paers from #arxiv (the Holly Bible man...).
◯ Why GraphRAG Beats Plain RAG: 4 Hard Facts ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
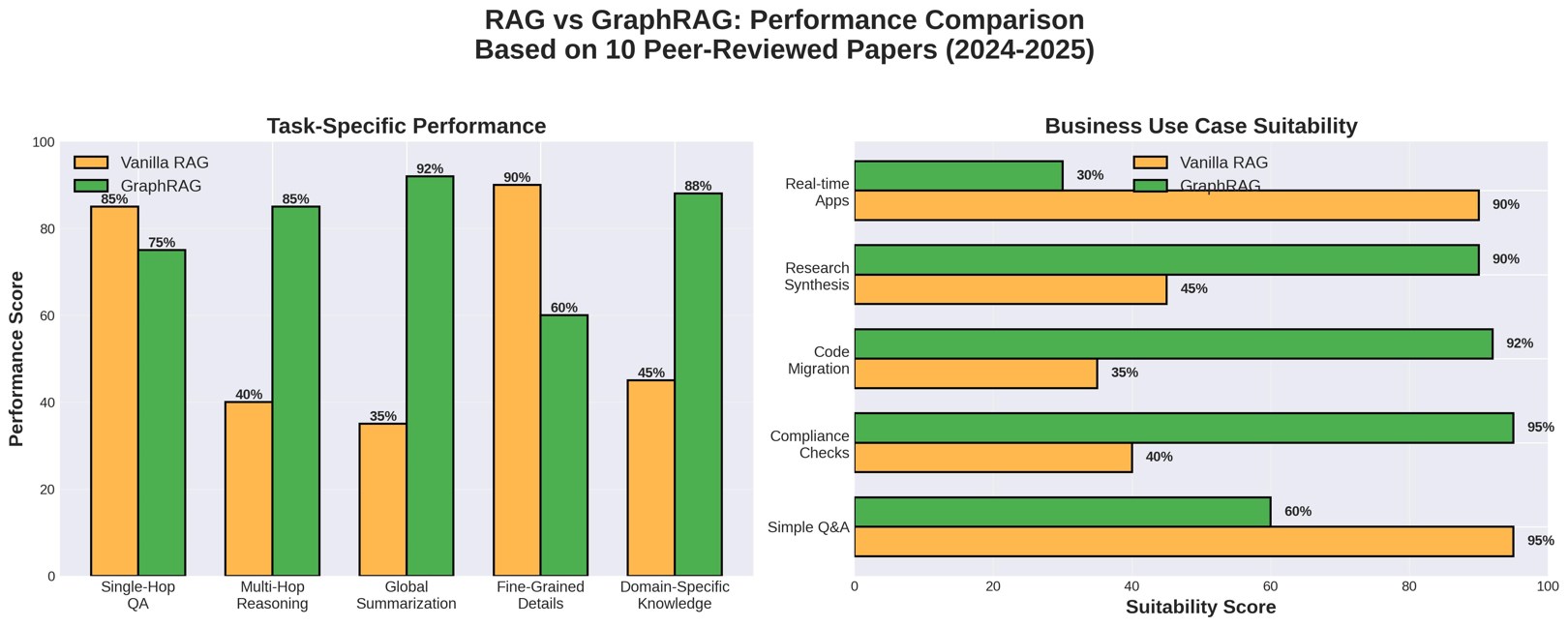
⟶ Multi-Hop Reasoning: GraphRAG Doubles Performance
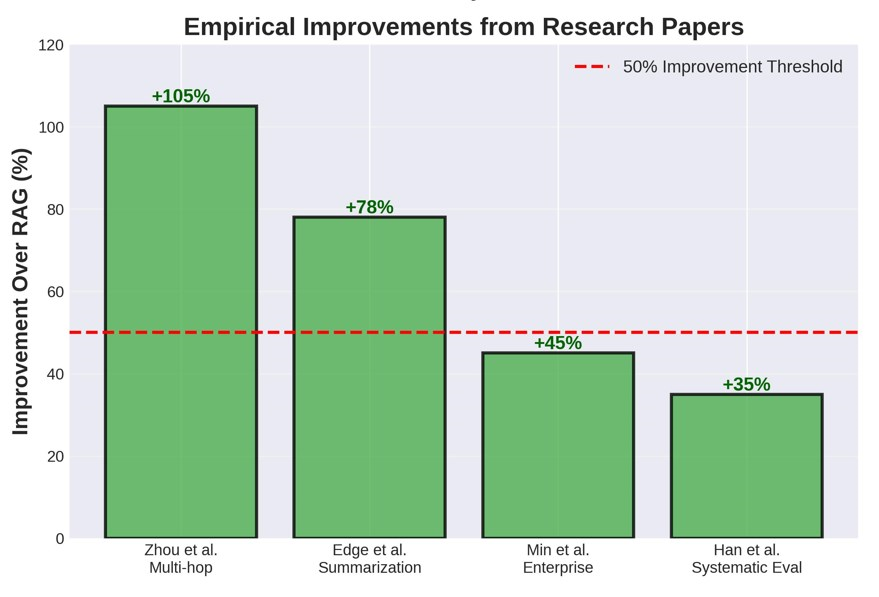
Zhou et al. (2025) showed that optimized GraphRAG doubled performance on difficult multi-hop questions—from 15.26% to 31.44% on the GRBench benchmark. That's not a marginal gain; that's game-changing.
Why? Because vanilla RAG retrieves based on similarity. GraphRAG traverses semantic paths, assembling chains of evidence that actually connect the dots.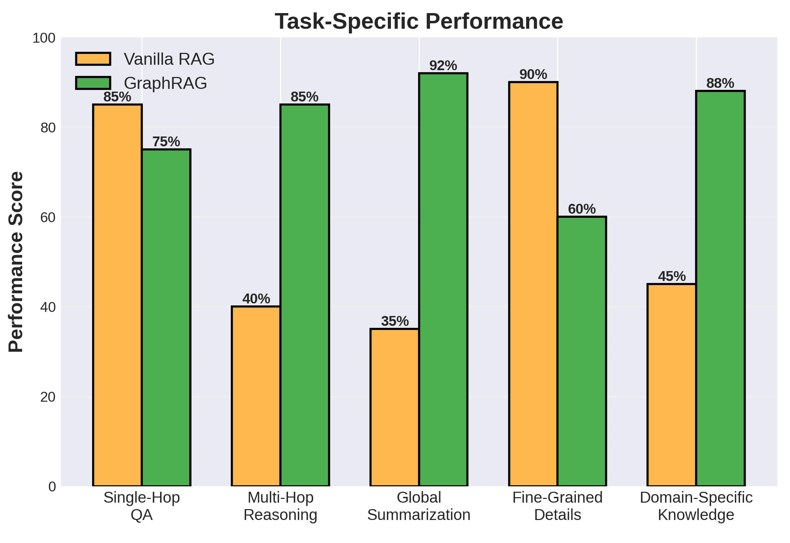
The proof: "Empirical results on the GRBench benchmark demonstrate a 64.7% improvement over traditional GraphRAG and a 30.3% improvement over previous graph traversal methods."
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
⟶ Global Summarization: Microsoft's 1M+ Token Victory
Edge et al. (2024)—the OG GraphRAG paper from Microsoft Research—demonstrated substantial improvements on comprehensiveness AND diversity when handling million-token datasets.
Here's the kicker: vanilla RAG fails on global questions like "What are the main themes in this dataset?" because it's designed for explicit retrieval, not query-focused summarization.
The quote: "For a class of global sensemaking questions over datasets in the 1 million token range, GraphRAG leads to substantial improvements over a conventional RAG baseline for both the comprehensiveness and diversity of generated answers."
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
⟶ Domain-Specific Knowledge: The Enterprise Sweet Spot
Min et al. (2025) from SAP Research deployed GraphRAG on real-world legacy code migration—the first enterprise application documented in peer-reviewed research.
The result? GraphRAG retrieval generated fewer hallucinations and faulty function definitions compared to dense vector retrieval. In enterprise contexts where accuracy = $$, this matters.
The finding: "From our error analysis we observe that the migrated code generated by dense vector retrieval exhibits more hallucinations and faulty function definitions compared to that generated using GraphRAG-based retrieval."
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
⟶ The Cost Trade-Off (Yes, It's Real)
Here's where I keep it 💯: GraphRAG construction is computationally expensive. A Survey by Zhang et al. (2025) explicitly documents this:
"RAG systems can be computationally expensive and time-consuming, especially when dealing with large-scale knowledge sources... graph retrieval-augmented generation (GraphRAG) has recently emerged as a new paradigm."
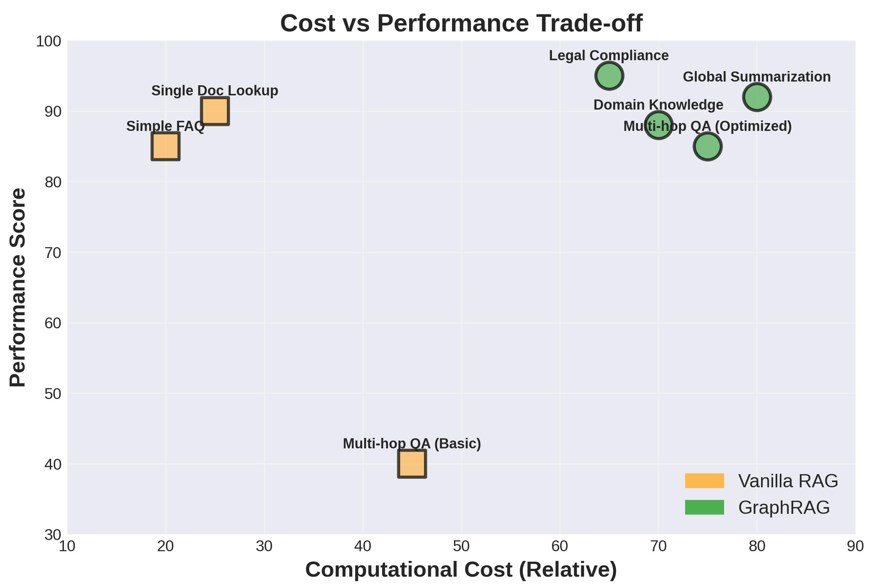
BUT—Min et al. (2025) showed that dependency parsing achieves 94% of LLM-based performance at drastically reduced costs. So the "it's too expensive" argument? That's 2024 thinking.
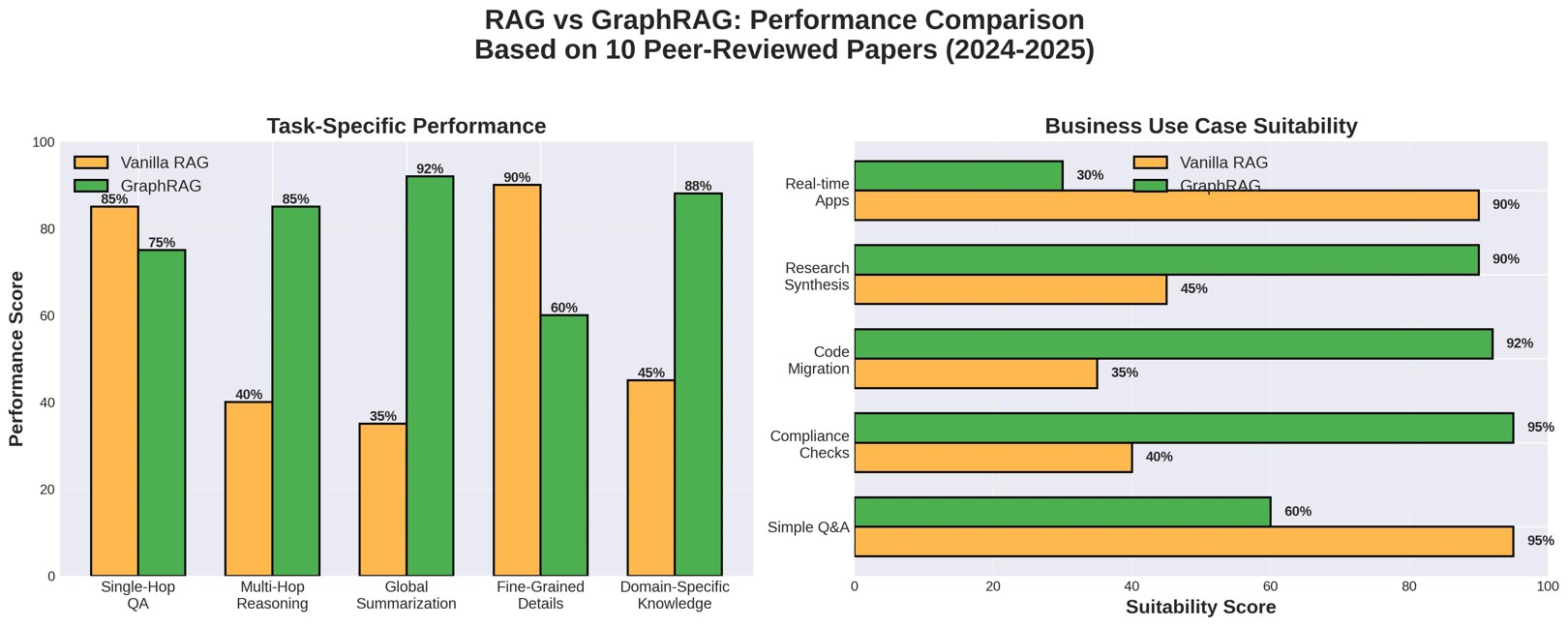
◯ Business Cases Where You NEED GraphRAG
⟶ Use Case #1: Multi-Hop Enterprise Reasoning
When to deploy: Legal compliance checks, supply chain analytics, technical troubleshooting. Han et al. (2025) found that:
"RAG performs better on single-hop questions and those requiring fine-grained details, whereas GraphRAG is more effective for multi-hop and reasoning-intensive questions."
Real talk: If your client's questions sound like "What's the impact of Regulation X on Supplier Y's Q3 deliverables given Contract Z?" — they need GraphRAG. Period.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
⟶ Use Case #2: Knowledge-Intensive Domains (Medical, Legal, Technical)
When to deploy: Healthcare documentation, legal research, engineering knowledge bases
Xiao et al. (2025) created GraphRAG-Bench with 16 college-level disciplines and found:
"All GraphRAG methods significantly enhance the reasoning capabilities of LLMs: through distinct algorithmic designs, these methods retrieve not only semantically relevant corpus for questions but also identify multi-hop dependent corpus in the knowledge base, providing evidential support for LLM reasoning."
The edge: Domain-specific terminology + hierarchical relationships = GraphRAG territory.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
⟶ Use Case #3: Global Context Synthesis (>500K Tokens)
When to deploy: Corporate intelligence reports, research synthesis, strategic planning
Zhang et al. (2025) designed GraphRAG-Bench specifically for:
"Comprehensive corpora with different information density, including tightly structured domain knowledge and loosely organized texts... tasks of increasing difficulty, covering fact retrieval, multi-hop reasoning, contextual summarization, and creative generation."
The insight: If the answer requires understanding the whole picture, not just retrieving chunks—GraphRAG wins.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
⟶ Use Case #4: Relational Dependencies (Entity-Heavy Contexts)
When to deploy: Social network analysis, organizational charts, product ecosystems
Han et al. (2024) - Survey explains:
"GraphRAG enables traversal over semantically meaningful paths, allowing the system to assemble chains of evidence and deliver coherent, multi-step responses."
The math: Questions like "Who reports to whom and why does it matter?" = graph problem, not similarity search.
◯ When Plain RAG Is Actually Fine
Alright, let's be honest. You don't need GraphRAG for:
⤷ Simple FAQ-style queries ("What's our return policy?") ⤷ Single-document lookups ("Find section 3.2 in the manual") ⤷ High-frequency, low-complexity Q&A (customer support bots) ⤷ Real-time applications with <500ms latency requirements ⤷ Cost-sensitive POCs where "good enough" is actually good enough
Han et al. (2025) confirms:
"RAG performs better on single-hop questions and those requiring fine-grained details."
⚠ Buuu..uT ... Here's the Thing (And This Is Important...)
These "plain RAG" use cases are becoming the minority in enterprise AI.
Why? Because data correlation is the new competitive moat.
⤷ Modern enterprises operate across multiple systems (CRM + ERP + SCM + HR)
⤷ Regulations require cross-document compliance (Sarbanes-Oxley, GDPR, etc.)
⤷ Competitive intelligence demands synthesis, not retrieval ⤷ AI copilots need contextual coherence, not keyword matching
Zhang et al. (2025) - Survey hits this nail on the head:
"Since large-scale knowledge sources often contain a significant amount of non-domain-specific information and domain-specific terms are usually sparsely distributed across diverse knowledge carriers, the retrieval module of RAG systems often needs to search through a vast amount of unstructured text... This makes resource consumption a persisting issue for traditional RAG, affecting its scalability."
Translation: If your company's knowledge graph looks like a hairball of interconnected systems, you're already in GraphRAG territory—you just don't know it yet.
That's all Folks (buuut.. i think now you can make your own choices...).
◯ All Papers Referenced ━━━━━━━━━━━━━━━━━━━━
- Zhou et al. (2025) - Inference Scaled GraphRAG
- Edge et al. (2024) - From Local to Global (Microsoft)
- Min et al. (2025) - Towards Practical GraphRAG (SAP)
- Zhang et al. (2025) - Survey of Graph RAG
- Han et al. (2025) - RAG vs GraphRAG: Systematic Evaluation
- Xiao et al. (2025) - GraphRAG-Bench
- Zhang et al. (2025) - When to Use Graphs in RAG
- Han et al. (2024) - Retrieval-Augmented Generation with Graphs (Survey)